Introduction
In this article, we will understand what is PDF GPT and how to build build your personal PDF Chat Assistant through simple steps.
Artificial Intelligence has taken center stage in the tech world since the revolutionary ChatGPT was introduced in late 2022. The groundbreaking model captivated many ideas and possibilities in developers and there has been an uprise in wide range implementation of these Large Language Models(LLMs).
At the heart of all these possibilities lies the LangChain framework that simplifies the development of applications powered by these language models. Many LLM applications require user-specific data that is not part of the model’s training set. One such is PDF GPT.
You can watch this video tutorial to build Personal PDF Chat Assistant:
Quick Start to PDF GPT
As discussed LangChain makes it easy to develop LLM-powered applications, But how? Lets us know how by understanding the components of LangChain.
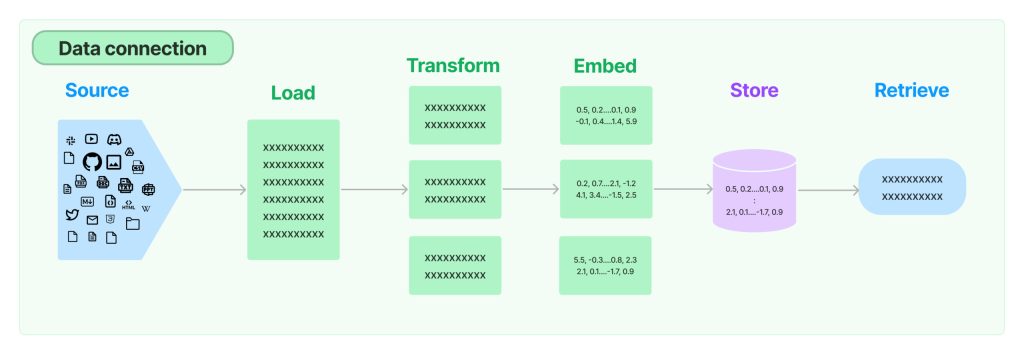
Data Aware: Connect Language Model to Other Sources of Data
Most LLM applications need user-specific data (Same in the case of PDF GPT, Business Data Analyzer, Query Builder, AI coder, etc. ) that are not part of the model’s training data. LangChain provides building blocks to connect data to the model. We’ll discuss all 5 steps of Data Connection in detail while we build the assistant.
Agent: Allow a Language Model to interact with its Environment
An Agent is a system that decides what action is taken by LLM, it observes and repeats until it reaches the correct answer. It allows us to combine LLMs capabilities with external sources of computation(tools) or knowledge. To use agents, we require three things: 1) A base LLM, 2) A tool to take on action, and 3) An agent to control and initiate actions and interactions.
There is also Chains. Assume chains are assembling other components of LangChain in particular ways to accomplish specific use cases. These components can even be other chains, models, memory, and Agents.
Tools are functions that agents can use to interact with the world. These tools can be generic utilities (e.g. search), other chains, or even other agents.
Virtual Environment Setup
Setting up a Virtual Environment is necessary to avoid version conflicts of packages between different projects that one might work on.
First, we will create a virtual environment. Navigate to the directory where you want to place the virtual environment, create a project folder, cd to the project folder in the terminal, and run the following command in the command prompt:
python -m venv <virtual-environment-name>Once you create the virtual environment, you need to activate it before you can use it in the project. On a Mac, run
source <VIRTUAL-ENVIRONMENT-NAME>/bin/activateOn a Windows run
.\<VIRTUAL-ENVIRONMENT-NAME>\Scripts\activateWhen you activate the virtual environment, the name of the environment will appear on the left side of the terminal. This indicates that the virtual environment is currently live. In the terminal, you can run the command “pip list” to check the base packages that are present when you create a new virtual environment.

Building PDF GPT Chat Assistant
Now that we have our virtual environment active, it is time to install the required packages from the terminal, create a main.py file in our project folder, and import these packages. Use Visual Studio Code (VSCode) for editing code as it is development-friendly.
Install and Import Packages
First, we will install by running the following command in the command prompt:
pip install gradio openai numpy tiktoken langchain unstructured
Now we will Import Packages:
import gradio as gr
import openai
import numpy as np
from time import sleep
import tiktoken
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import UnstructuredPDFLoaderWe will be using Gradio for the front end of the PDF GPT. Gradio is one of the best ways to make your machine-learning projects more interactive. OpenAI API key to send API requests to OpenAi’s Chat GPT. Tiktoken is a Byte-pair encoding (BPE) tokenizer, it splits text strings into tokens that can be passed to GPT models. GPT models see text in the form of tokens.
RecursiveCharacterTextSplitter will split documents recursively by different characters – starting with “\n\n”, then “\n”, then ” “. Important parameters to know here are chunkSize and chunkOverlap. chunkSize controls the max size (in terms of the number of characters) of the final documents. chunkOverlap specifies how much overlap there should be between chunks.
We obtain the final output from the raw text input as a list of documents formed based on chunk size and chunk overlap. UnstructuredPDFLoader uses Python’s unstructured package under the hood which provides components to process PDFs, HTML, and Word Documents.
COMPLETIONS_MODEL = "gpt-3.5-turbo"
EMBEDDING_MODEL = "text-embedding-ada-002"We choose the “gpt-3.5-turbo” model to generate answers and the “text-embedding-ada-002” model to generate vector representations that capture the semantic meaning of the text. Later these embeddings are used to compare the similarity between two different pieces of text. Get your key from platform.openai:
# Initialize the OpenAI API
openai.api_key = "<Your_OPENAI_APIKEY>"Extract Text from the PDF Function
# Function to convert a PDF to text
def extract_text_from_pdf(pdf_file, progress=gr.Progress()):
try:
reader = UnstructuredPDFLoader(pdf_file.name)
data = reader.load()
text = data[0].page_content
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=400,
chunk_overlap=50,
length_function=len,
)
chunks = text_splitter.create_documents([text])
embed = compute_doc_embeddings(chunks, progress)
return chunks, embed, "uploaded"
except Exception as e:
print(e)
return None, None, ""The extract_text_from_pdf function takes two parameters as input one the pdf_file object and the progress object that will track any tqdm iterations with the library in function which will help us get the progress of the embedding process of the pdf.
We use UnstructuredPDFLoader to extract content from pdf and store it in a reader object. We call the load method on the reader to retrieve all the content i.e. data from the pdf file and store it in the data variable. data[0].page_content is used to store all the text data of the first document(In this case there is only one document that is uploaded pdf) in the data variable in a variable named “text”.
After extracting all the text from the PDF document, we use the RecursiveCharacterTextSplitter to create chunks of our text data. Each chunk consists of 400 words, with a 50-word overlap between consecutive chunks.
We will use a compute_doc_embeddings function within the function that will take all the chunks as input and the progress object as input. We want the function to return a dictionary of embeddings of each chunk. The function is defined further in the code.
The extract_text_from_pdf function covers the text extraction and processing part of the data connection process.
Function to Generate Embeddings
def get_embedding(text, model=EMBEDDING_MODEL):
result = openai.Embedding.create(
model=model,
input=text
)
return result["data"][0]["embedding"]get_embedding function generates embeddings for text using EMBEDDING_MODEL.
compute_doc_embeddings() Function
def compute_doc_embeddings(text, progress):
"""
Create an embedding for each row in the dataframe using the OpenAI Embeddings API.
Return a dictionary that maps between each embedding vector and the index of the row that it corresponds to.
"""
result = {}
for idx in progress.tqdm(range(len(text))):
try:
res = get_embedding(text[idx].page_content)
except:
done = False
while not done:
sleep(5)
try:
res = get_embedding(text[idx].page_content)
done = True
except:
pass
result[idx] = res
return resultYou probably got the functionality from the comments. The function gets text chunks and progress object as input. For each chunk, we extract embeddings using OpenAi embeddings and store in result with the corresponding index. The function returns a dictionary of embeddings with each embedding mapping to the index of the corresponding chunk.
Hooray! Now that we have defined compute_doc_embeddings, we have covered four steps of the data connection process: text extraction, processing, embedding, and storing. For easing storing and retrieving steps there are various vector store database options such as Pinecone, Chromadb, etc.
Retrieving from Source PDF
The functions defined until now act as the base data storage of our chatbot. For retrieving data, the most important text is user query/user input/ user question. When you search for information, formula, or a topic on Google you get results based on keywords, based on your location, etc.
The retrieval method widely used to obtain relevant source documents for user input is vector similarity search. It could be by getting the dot product of vectors or it could be by calculating cosine similarity. After calculating all the vector similarity scores, we arrange them in decreasing order of similarity magnitude and select the top n similar documents.
def vector_similarity(x, y):
"""
Returns the similarity between two vectors.
Because OpenAI Embeddings are normalized to length 1, the cosine similarity is the same as the dot product.
"""
return np.dot(np.array(x), np.array(y))
def order_document_sections_by_query_similarity(query, contexts):
"""
Find the query embedding for the supplied query, and compare it against all of the pre-calculated document embeddings
to find the most relevant sections.
Return the list of document sections, sorted by relevance in descending order.
"""
query_embedding = get_embedding(query)
document_similarities = sorted([
(vector_similarity(query_embedding, doc_embedding), doc_index) for doc_index, doc_embedding in contexts.items()
], reverse=True)
return document_similaritiesConstruct Prompt from Question and context_embeddings
A Prompt is an input that we pass to the language model. For a specific use case, one generally constructs it using a prompt template that takes in certain parameters and generates the desired prompt. This prompt serves as input to the Language Model (LLM). A prompt can contain instructions, few-shot examples, question input, context from the user, and everything the language model needs to generate better answers.
SEPARATOR = "\n* "
ENCODING = "gpt2" # encoding for text-davinci-003
encoding = tiktoken.get_encoding(ENCODING)
separator_len = len(encoding.encode(SEPARATOR))
COMPLETIONS_API_PARAMS = {
# We use temperature of 0.0 because it gives the most predictable, factual answer.
"temperature": 0.0,
"max_tokens": 300,
"model": COMPLETIONS_MODEL,
}
def construct_prompt(question, context_embeddings, df):
"""
Fetch relevant
"""
chosen_sections = []
chosen_sections_len = 0
chosen_sections_indexes = []
most_relevant_document_sections = order_document_sections_by_query_similarity(question, context_embeddings)
if "email" in question:
MAX_SECTION_LEN = 2500
COMPLETIONS_API_PARAMS['max_tokens'] = 1000
COMPLETIONS_API_PARAMS['temperature'] = 0.5
header = """Write email using the provided context \n\nContext:\n """
elif "summary" in question or "summarize" in question:
MAX_SECTION_LEN = 2500
COMPLETIONS_API_PARAMS['max_tokens'] = 1000
COMPLETIONS_API_PARAMS['temperature'] = 0.5
header = """Write detailed summary of the provided context \n\nContext:\n """
question = ""
else:
MAX_SECTION_LEN = 1000
COMPLETIONS_API_PARAMS['max_tokens'] = 300
COMPLETIONS_API_PARAMS['temperature'] = 0.0
header = """Answer the question in detail as truthfully as possible, and if the answer is not contained within the text below, say "I don't know."\n\nContext:\n """
for _, section_index in most_relevant_document_sections:
# Add contexts until we run out of space.
document_section = df[section_index].page_content
chosen_sections_len += len(document_section) * 0.25 + separator_len
if chosen_sections_len > MAX_SECTION_LEN:
break
chosen_sections.append(SEPARATOR + document_section.replace("\n", " "))
chosen_sections_indexes.append(str(section_index))
# Useful diagnostic information
print(f"Selected {len(chosen_sections)} document sections:")
print("\n".join(chosen_sections_indexes))
return header + "".join(chosen_sections) + "\n\n Q: " + question + "\n A:"We use a dictionary ‘COMPLETIONS_API_PARAMS’ to pass parameters while calling ChatGPT API. In the function, you can observe we have conditioned the function to pass different parameters for different categories in questions. You can always add more conditions that are suitable for your use. In the loop of most_relevant_documents, we have multiplied len(document_section) by 0.25 assuming each word to have 4 characters to keep track on MAX_SECTION_LEN.
Final step: Answering User Questions with PDF GPT
def answer_query_with_context(
query,
df,
document_embeddings, history,
openchat, show_prompt=True
):
history = history or []
prompt = construct_prompt(
query,
document_embeddings,
df
)
if show_prompt:
print(prompt)
openchat = openchat or [{"role": "system", "content": "You are a Q&A assistant"}]
openchat.append({"role": "user", "content": prompt})
response = openai.ChatCompletion.create(
messages=openchat,
**COMPLETIONS_API_PARAMS
)
openchat.pop()
openchat.append({"role": "user", "content": query})
print(COMPLETIONS_API_PARAMS)
output = response["choices"][0]["message"]["content"].replace('\n', '<br>')
openchat.append({"role": "assistant", "content": output})
history.append((query, output))
return history, history, openchat, ""By looking at the function it is evident that this function uses constructed prompt, document embeddings, and chat history to generate appropriate responses from OpenAI API call to ChatGPT.To understand this function better let’s follow the gradio interface code.
Gradio Interface of PDF GPT
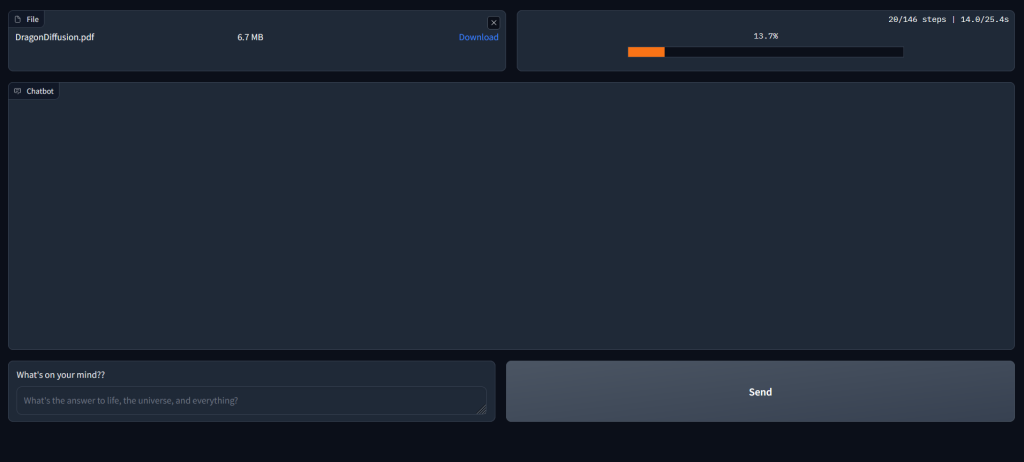
with gr.Blocks() as app:
history_state = gr.State()
document = gr.Variable()
embeddings = gr.Variable()
chat = gr.Variable()
with gr.Row():
upload = gr.File(label=None, interactive=True, elem_id="short-upload-box")
ext = gr.Textbox(label="Progress")
with gr.Row():
with gr.Column(scale=3):
chatbot = gr.Chatbot().style(color_map=("#075e54", "grey"))
with gr.Row():
message = gr.Textbox(label="What's on your mind??",
placeholder="What's the answer to life, the universe, and everything?",
lines=1)
submit = gr.Button(value="Send", variant="secondary").style(full_width=False)
upload.change(extract_text_from_pdf, inputs=[upload], outputs=[document, embeddings, ext])
message.submit(answer_query_with_context, inputs=[message, document, embeddings, history_state, chat],
outputs=[chatbot, history_state, chat, message])
submit.click(answer_query_with_context, inputs=[message, document, embeddings, history_state, chat],
outputs=[chatbot, history_state, chat, message])
if __name__ == "__main__":
app.queue().launch(debug=True)gr.blocks() sets up the user interface of PDFGPT, it includes a file upload box, a textbox to display progress towards completing document embedding, A textbox for the user to input questions,a submit button, and a chatbot interface to display chat.
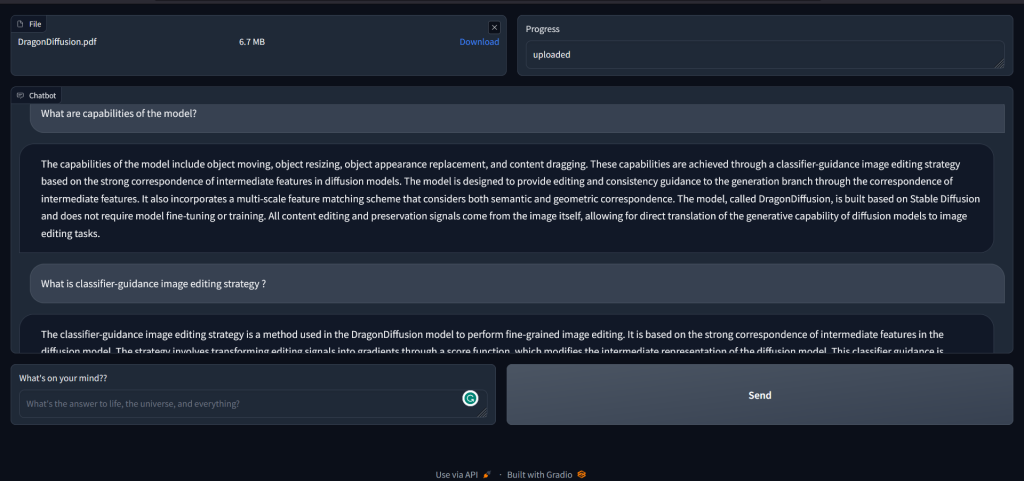
upload.change() initiates the update of embeddings, and documents when a new pdf file is uploaded. Whenever a new pdf is uploaded the function extract_text_from_pdf is called with file object as input and its outputs are [document, embeddings, ext].
message.submit() calls the answer_query_with_context function when a user submits a query by pressing the ‘ENTER’ key. This function takes [message, document, embeddings, history_state, chat] as input. At the beginning of the Gradio code, we initialized four variables. The history_state is initialized as gr.state(), and it stores the chat history of the current session.
It initializes history as the chat session starts and in answer_query_with_context function it is updated with each (query, output). The query is sent to the answer_query_with_context function, where it is converted into a suitable prompt template and then appended openchat as a message. This message, along with the parameters, is passed to the text generator (openai.ChatCompletion.create()) to obtain a response.
message.submit() and submit.click() serve the same purpose. One initiates the function when the ‘ENTER’ key is pressed while the other initiates when submit button is clicked.
Conclusion
This article tries to provide a step-by-step and comprehensive explanation about how you can build your own PDFGPT. It also provides all the necessary information about components of the chat assistant which are LangChain, openai, GPT-3.5-turbo model(or ChatGPT), Gradio for the interface, tiktoken for embedding. I suggest you backtrack the code from the Gradio interface which will help you gain intuition.
Some exciting reads, Relevant Resources on Langchain, and Artificial Intelligence :
Document Summarization using Langchain
Unlocking Quick Data Insights With Pandas and CSV Agents Of LangChain
LangChain: Introduction| Pinecone